AmazonWebService実践入門を読んで実践する「その1:I/Oの高速化」続き2
「その1:I/Oの高速化」の結果検証
前回のブログに記載した結果が、検証前仮説と異なる結果になったため、詳細に検証・分析してみたいと思います。
ログの内容を見比べる
- bw(帯域幅)が、IO1(プロビジョンドIOPS)の場合だけ、1/5ぐらい低い。

- 4タイプ(Sequential-Read、Sequential-Writes、Random-Read、Random -Writes)の帯域幅を合計した値で ストレージタイプごとのbw(帯域幅)を見るとよくわかる。

ボトルネックを解消する
* 帯域幅がボトルネックになっているときは、EBS最適化オプションを使うことを「AmazonWebService実践入門」ではおすすめしていた。
EBS最適化オプションを使う。
- EBS最適化オプションとは…EC2インスタンスとEBSボリュームはネットワークを介して接続されているが、そのネットワークはEBSへのアクセス以外のアクセスにも利用されている。そのネットワーク帯域を占有して、EBSへのアクセスを最大化するためのオプションがEBS最適化オプションである。
EBS最適化オプションを適用する。
インスタンスタイプをt2.microで利用していたため、EBS最適化オプションの利用できるタイプにインスタンスタイプを変更する必要があった。そのため、以下の手順で『m4.large』へ変更した。
①AWSマネジメントコンソールから、インスタンスを停止して、「アクション」→「インスタンスの設定」→「インスタンスタイプの変更」を選択する。

- ②次に出てきたモーダルウィンドウでEBS最適化にチェックの入っているインスタンスタイプを選択する。

※EBS最適化オプションが利用できるインスタンスタイプは限られている。詳細は、こちらへ
※また、EBS最適化オプションを適用する方法は、こちらの公式ページにも掲載されています。
再計測
インスタンスの状態を『m4.large』+「EBS最適化オプションをオン」にして、再計測しました。
結果:まったく変わらず。
HDDにおいては、エラーになり、ログ記録が全くされていない。
汎用SSDは、Read、Randreadしか記録されない。という状態。
ORZ
うーん。何がいけないのか。。。もう一度再考が必要。
計測方法の再考
本に書かれているベンチマークの方法と違いを探してみる。
- 1インスタンスにボリュームを複数アタッチしている。
- ブロックサイズが小さい。
- directオプションを利用している。
- numjobsオプションを利用している。
- runtimeオプションを利用している。
- group_reportingオプションを利用している。
- 対象ディレクトリが違う。
ということでこのあたりを教科書通りにして再度チャレンジしてみる。 今日はここまで。
AmazonWebService実践入門を読んで実践する「その1:I/Oの高速化」続き
前編はこちらへ
前回の続きで、 AmazonWebService実践入門の本にあるI/O高速化の方法をベンチマークを使って試してみる。 のですが、まずは、その方法と取りうる選択肢を列挙してみます。
AWSでのI/O高速化の方法
| 手段 | 解説 | 遅い→→→→ | →→→→→→→→ | →→→→早い | |
|---|---|---|---|---|---|
| 1. | EC2のストレージタイプの選択 | EBS | インスタンスストア | ||
| 2. | EC2のボリュームタイプの選択 | マグネティック | SSD(汎用) | SSD(プロビジョンドIOPS) | |
| 3. | EBS最適化オプションの選択 | EC2とEBSの間のネットワークを占有できるオプション。 ロビジョンドIOPSを使用するときは ネットワークがボトルネックになる場合が多いので、 このオプションを併用するようにしましょう。 また、EBS最適化オプションは比較的大きなサイズの インスタンスでないと利用できない。 |
なし | あり | |
| 4. | RAID0によるスクレイピング | EBSでは1つのボリュームにおける容量や IOPSには限界があります。 それを超えたパフォーマンスを求める場合、 RAID0でのストライピングが有効です。 |
なし | あり | |
| 5. | ボリュームの暖機 | EBSボリュームでは、 そのブロックへ初めてアクセスされる前に、 準備処理が行われます。 あらかじめこの準備処理を済ませておくことで、 最初からベストパフォーマンスで 稼働させることができます。 |
なし | あり |
3,4,5はすべてEBSボリュームについてのことであり、特定の条件下で効果を発揮するものの様子なので、 まずは、基本的な1,2のみでの以下の比較をしてみようと思います。
検証パターン
- ①EBS+マグネティック
- ②EBS+SSD汎用
- ③EBS+SSD(プロビジョンドIOPS)
- ④インスタンスストア+マグネティック
- ⑤インスタンスストア+SSD汎用
- ⑥インスタンスストア+SSD(プロビジョンドIOPS)
検証する際のその他諸条件
- インスタンスタイプはすべてのパターンで同じ「t2.micro」にする。
- ボリュームのサイズはすべてのパターンで同じ「8 GiB」にする。
- プロビジョンドIOPSのIOPS設定値は、100/3000とする。(100~20000でないといけないため)
jobファイルその1-(/home/ec2-user/fio-scenario1.fio)
[Sequential-Read] rw=read directory=/tmp/ size=1G blocksize=512k ioengine=libaio buffered=0 [Sequential-Writes] rw=write directory=/tmp/ size=1G blocksize=512k ioengine=libaio buffered=0 [Random-Read] rw=randread directory=/tmp/ size=1G blocksize=512k ioengine=libaio buffered=0 [Random -Writes] rw=randwrite directory=/tmp/ size=1G blocksize=512k ioengine=libaio buffered=0
jobファイルその2-ioengine=sync(/home/ec2-user/fio-scenario1.fio)
[Sequential-Read] rw=read directory=/tmp/ size=1G blocksize=512k ioengine=sync buffered=0 [Sequential-Writes] rw=write directory=/tmp/ size=1G blocksize=512k ioengine=sync buffered=0 [Random-Read] rw=randread directory=/tmp/ size=1G blocksize=512k ioengine=sync buffered=0 [Random -Writes] rw=randwrite directory=/tmp/ size=1G blocksize=512k ioengine=sync buffered=0
jobファイルその3 buffered=1 -ioengine=sync(/home/ec2-user/fio-scenario3.fio)
[Sequential-Read] rw=read directory=/tmp/ size=1G blocksize=512k ioengine=sync buffered=1 [Sequential-Writes] rw=write directory=/tmp/ size=1G blocksize=512k ioengine=sync buffered=1 [Random-Read] rw=randread directory=/tmp/ size=1G blocksize=512k ioengine=sync buffered=1 [Random -Writes] rw=randwrite directory=/tmp/ size=1G blocksize=512k ioengine=sync buffered=1
実行コマンド
fio /home/ec2-user/fio-scenario1.fio > /home/ec2-user/PATTERN1-`date +%Y%m%d_%H-%M-%S`.log fio /home/ec2-user/fio-scenario2.fio > /home/ec2-user/PATTERN2-`date +%Y%m%d_%H-%M-%S`.log fio /home/ec2-user/fio-scenario3.fio > /home/ec2-user/PATTERN3-`date +%Y%m%d_%H-%M-%S`.log
- パターンの番号は別途記載しなおす。
検証前仮説
検証結果

考察
以下の事象は本来逆の状態になるはず。設定がなにか違っている感じがする。
- なぜか、SSD(プロビジョンドIOPS)のほうがIOPSが下がっている。
- シーケンシャルとランダムで差がない。
改めて、設定を見直して検証したいと思います。 続報はまた今度。
AmazonWebService実践入門を読んで実践する「その1:I/Oの高速化」
AmazonWebService実践入門の本にあるI/O高速化の方法をベンチマークを使って試してみる。
方法:I/Oが遅い選択肢から順に早くさせていく。
本で紹介されている高速化の方法
- EC2のストレージタイプの選択
- EC2のボリュームタイプの選択
- EBS最適化オプションの選択
- RAID0によるスクレイピング
- ボリュームの暖機
まずは、fioを試しに使ってみる
ベンチマークコマンドをインスト―ル。
# rootになる sudo su # yumのアップデートする yum clean all yum -y update # fioのインストール yum install libaio-devel wget http://pkgs.repoforge.org/fio/fio-2.0.14-1.el5.rf.x86_64.rpm rpm -Uvh fio-2.0.14-1.el5.rf.x86_64.rpm rpm -qa | grep fio # fioインストール確認 which fio
fioの実行結果
[root@ip-172-31-26-155 ec2-user]# fio ./fileio_bench/random-read.fio
random-read: (g=0): rw=randread, bs=4K-4K/4K-4K/4K-4K, ioengine=sync, iodepth=1
fio-2.0.14
Starting 1 process
random-read: Laying out IO file(s) (1 file(s) / 100MB)
random-read: (groupid=0, jobs=1): err= 0: pid=7160: Thu Feb 11 16:10:52 2016
read : io=102400KB, bw=2173.1MB/s, iops=556521 , runt= 46msec
clat (usec): min=0 , max=24 , avg= 1.09, stdev= 0.77
lat (usec): min=0 , max=24 , avg= 1.21, stdev= 0.79
clat percentiles (usec):
| 1.00th=[ 0], 5.00th=[ 0], 10.00th=[ 1], 20.00th=[ 1],
| 30.00th=[ 1], 40.00th=[ 1], 50.00th=[ 1], 60.00th=[ 1],
| 70.00th=[ 1], 80.00th=[ 1], 90.00th=[ 2], 95.00th=[ 2],
| 99.00th=[ 3], 99.50th=[ 3], 99.90th=[ 13], 99.95th=[ 14],
| 99.99th=[ 21]
lat (usec) : 2=88.38%, 4=11.12%, 10=0.34%, 20=0.14%, 50=0.02%
cpu : usr=17.78%, sys=71.11%, ctx=7, majf=0, minf=4
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=25600/w=0/d=0, short=r=0/w=0/d=0
Run status group 0 (all jobs):
READ: io=102400KB, aggrb=2173.1MB/s, minb=2173.1MB/s, maxb=2173.1MB/s, mint=46msec, maxt=46msec
Disk stats (read/write):
xvda: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%
[root@ip-172-31-26-155 ec2-user]#
おーいろいろ結果が出てるがさっぱり意味がわからん。 fioコマンドのことを学ばねば。。。 ということで↓でまずはfioコマンドをお勉強。
fioコマンド
はじめに
AWSのディスクI/0の高速化をテーマにした実践をするために、 まずは、その実践で使うディスクI/Oを計測するベンチマーク測定ツール「fioコマンド」についてお勉強。
fioコマンドとは
由来
flexible I/O tester
FileI/Oの略なんだと思ってたら、 「flexible I/O tester」の略なんだと。
作者・開発元
Jens Axboe
WikiPediaによるとLinuxカーネルのハッカーらしい。今はORACLEに在籍している様子。 1976年生まれ。(近い!同じ世代でこんなもの作っちゃう人。同じ人間に思えない。)
最新バージョン
2.6(記事投稿時点での最新)
Releases · axboe/fio · GitHub によると、記事投稿日から18日前に2.6がリリースされている様子。
概要
- ディスクI/Oに負荷をかけるためにスレッドやプロレスをうじゃうじゃ起動でき、設定された分のFIOの負荷をかけることができる。
- linux版だけでなく、windows版もある。http://www.bluestop.org/fio/
コマンド構文
fio [options] [jobfile]...
コマンドオプション
- --debug
- Enable some debugging options (see below)
- デバックモードにする
- --parse-only
- Parse options only, don't start any IO
- 決められたフェーズのみ負荷をかける設定ができる?っぽい。
- --output
- Write output to file
- 結果出力先の指定
- --runtime
- Runtime in seconds
- 実行時間の指定
- --bandwidth-log
- Generate per-job bandwidth logs
- 1ジョブごとに帯域幅を測定する
- --minimal
- Minimal (terse) output
- 最小の簡易出力
- --output-format=type
- --terse-version=type
- Terse version output format (default 3, or 2 or 4).
- 簡単モードで使うバージョン?
- --version
- Print version info and exit
- バージョン情報の出力
- --help
- Print this page
- ヘルプ
- --cpuclock-test
- Perform test/validation of CPU clock
- CPUクロックの確認をする
- --crctest[=test]
- Test speed of checksum functions
- チェックサムのテスト時間を計測する
- --cmdhelp=cmd
- Print command help, "all" for all of them
- コマンドのヘルプ。
- --enghelp=engine
- Print ioengine help, or list available ioengines
- エンジンのヘルプを出力する。
- --enghelp=engine,cmd
- Print help for an ioengine cmd
- エンジンのヘルプを出力する?
- --showcmd
- Turn a job file into command line options
- ジョブファイルにコマンドラインオプションの内容を追加する?
--eta=when
- When ETA estimate should be printed May be "always", "never" or "auto"
- 終了予定時間を出力する
--eta-newline=time Force a new line for every 'time' period passed
--status-interval=t Force full status dump every 't' period passed
--readonly
- Turn on safety read-only checks, preventing writes
- 読み取り処理のみチェック。書き込みを防ぐことができる。
- --section=name
- Only run specified section in job file
- ジョブファイルのしていされたセクションだけ実行する
- --alloc-size=kb
- Set smalloc pool to this size in kb (def 1024)
- 表示されるサイズ?
- --warnings-fatal
- Fio parser warnings are fatal
- warningはfaitalとして扱うか?
- --max-jobs=nr
- Maximum number of threads/processes to support
- 最大のスレッド・プロセス数
- --server=args
- Start a backend fio server
- 処理を開始するサーバ
- --daemonize=pidfile
- Background fio server, write pid to file
- バックグラウンドで実行するか?
- --client=hostname
- Talk to remote backend fio server at hostname
- リモートにあるサーバで実行する場合のホスト名指定
- --idle-prof=option
- Report cpu idleness on a system or percpu basis (option=system,percpu) or run unit work calibration only (option=calibrate)
- ?
- --inflate-log=log
- Inflate and output compressed log
- ログが増えたら圧縮する
- --trigger-file=file
- Execute trigger cmd when file exists
- ファイルで起動する場合のトリガーファイル。(ファイルが存在すれば実行する)
- --trigger-timeout=t
- Execute trigger af this time
- 時間で起動する場合のトリガー時間。
- --trigger=cmd
- Set this command as local trigger
- ?
- --trigger-remote=cmd Set this command as remote trigger ?
- --aux-path=path
- Use this path for fio state generated files
- ?
ジョブファイルのパラメータ
ここではよく利用しそうなもののみ紹介します。
すべてのパラメータを知りたい場合はこちらへ
ジョブファイル記述例
[random-read]→コメント rw=randread size=100m directory=/home/test/fio/
| パラメータ名 | 設定例 | パラメータ説明 |
|---|---|---|
| rw | rw=str | fioで読み書きする方法。詳細はこちらへ。 設定できる値は、read,write,randwrite,randread,rw,readwrite,randrw,trimwriteがある |
| randrepeat | randrepeat=bool | ランダムアクセスを規則的に行うか?設定できるっぽい。 ランダムアクセスでのベンチマークをするときにはfalseにしたほうがよさそう |
| randseed | randseed=int | ここで設定された値をもとに、乱数を発生させて、ランダムアクセスするらしい。 |
| ioengine | ioengine=str | IOをどう行うか決める。デフォルトはsync(同期I/O)になる。 syncかlibaioを使うことが多い様子。 Nullはデバックやテスト目的で利用。 |
| size | size=int | この測定で読み書きするファイルサイズ。 Job全体のIOサイズ。 単位はb。, 64{k,M, G, T, P}, 10% など |
| percentage_random | percentage_random=int | どのくらいの割合でランダムにするか設定できる。 100%にするとすべてランダム、0%だとすべてシーケンシャルになる。 読み取り、書き込み、トリムそれぞれに値を設定できる。 設定例:読み取りに50%書き込みに100%トリムは0%の場合は 「percentage_random=50,100,0」。 |
| nrfiles | nrfiles=int | このジョブで利用するファイル数を設定できる。デフォルトは1。 |
| overwrite | overwrite=bool | ファイルへの書き込みを上書きとするか、 全削除して新規書き込みとするかの選択。 1=true=上書きする。デフォルトは1(true) |
| runtime | runtime=time | 実行最大時間。単位はseconds(秒) |
| buffered | buffered=bool | バッファを利用するか否か。デフォルトは1(true) |
| iomem,mem | iomem=str,mem=str | バッファとして利用するメモリーのタイプ。 以下が選択できるらしい。 malloc 、shm 、shmhuge 、mmap 、mmaphuge 、mmapshared |
| verify_only | 実際の計測はしないで、確認用のモード。 | |
| lockmem | lockmem=int | 指定された量のメモリを未使用にできるらしい。メモリの少ない状態をシュミレートできるとのこと。 |
| rwmixread | rwmixread=int | 読み書きの割合。設定例:-rwmixread=70 70%read, 30%write |
| rwmixwrite | rwmixwrite=int | rwmixreadと一緒で引数の意味が逆なだけ |
| nice | nice=int | このコマンドのCPU優先順位を決定する。 ナイス値は-20~19であり-20がもっとも優先される。 デフォルトは10。 |
| rate | rate=int | ジョブで使用される帯域幅。数はバイト/秒。 |
| ratemin | ratemin=int | 最低限維持する帯域幅。 これを下回るとジョブが途中終了し失敗扱いになる。 |
インストール
fioのインストール
yum install fio
fioのバージョン確認
fio -v
> [ec2-user@ip-172-31-26-155 ~]$ fio -v > fio-2.1.5
使い方
- fioで読み書きするディレクトリを決める。または対象のディレクトリを作成する。
今回は、「/tmp/fio-test/」にします。 - jobファイルを作成して、必要なパラメータを記述する。今回は以下を設定。
[sample] rw=randread size=256m directory=/tmp/fio-test
- fioコマンドを実行する。
[ec2-user@ip-172-31-26-155 fio-benchmark]$ fio /home/ec2-user/fio-benchmark/sample.job
- 結果を検証する。
結果を見る
実行中ログ
sample: (g=0): rw=randread, bs=4K-4K/4K-4K/4K-4K, ioengine=sync, iodepth=1 fio-2.1.5 Starting 1 process Jobs: 1 (f=1) Jobs: 1 (f=1): [r] [15.8% done] [14808KB/0KB/0KB /s] [3702/0/0 iops] [eta 00m:16s] Jobs: 1 (f=1): [r] [22.2% done] [16144KB/0KB/0KB /s] [4036/0/0 iops] [eta 00m:14s] Jobs: 1 (f=1): [r] [29.4% done] [16920KB/0KB/0KB /s] [4230/0/0 iops] [eta 00m:12s] Jobs: 1 (f=1): [r] [35.3% done] [16688KB/0KB/0KB /s] [4172/0/0 iops] [eta 00m:11s] Jobs: 1 (f=1): [r] [41.2% done] [15428KB/0KB/0KB /s] [3857/0/0 iops] [eta 00m:10s] Jobs: 1 (f=1): [r] [47.1% done] [16232KB/0KB/0KB /s] [4058/0/0 iops] [eta 00m:09s] Jobs: 1 (f=1): [r] [52.9% done] [16208KB/0KB/0KB /s] [4052/0/0 iops] [eta 00m:08s] Jobs: 1 (f=1): [r] [58.8% done] [14892KB/0KB/0KB /s] [3723/0/0 iops] [eta 00m:07s] Jobs: 1 (f=1): [r] [64.7% done] [16392KB/0KB/0KB /s] [4098/0/0 iops] [eta 00m:06s] Jobs: 1 (f=1): [r] [70.6% done] [16036KB/0KB/0KB /s] [4009/0/0 iops] [eta 00m:05s] Jobs: 1 (f=1): [r] [76.5% done] [17300KB/0KB/0KB /s] [4325/0/0 iops] [eta 00m:04s] Jobs: 1 (f=1): [r] [82.4% done] [16436KB/0KB/0KB /s] [4109/0/0 iops] [eta 00m:03s] Jobs: 1 (f=1): [r] [88.2% done] [14764KB/0KB/0KB /s] [3691/0/0 iops] [eta 00m:02s] Jobs: 1 (f=1): [r] [94.1% done] [15028KB/0KB/0KB /s] [3757/0/0 iops] [eta 00m:01s] Jobs: 1 (f=1): [r] [100.0% done] [16340KB/0KB/0KB /s] [4085/0/0 iops] [eta 00m:00s]
実行結果
sample: (groupid=0, jobs=1): err= 0: pid=28707: Sun Feb 21 06:08:29 2016
read : io=262144KB, bw=15935KB/s, iops=3983, runt= 16451msec
clat (usec): min=166, max=41865, avg=249.06, stdev=375.48
lat (usec): min=166, max=41866, avg=249.25, stdev=375.48
clat percentiles (usec):
| 1.00th=[ 179], 5.00th=[ 185], 10.00th=[ 187], 20.00th=[ 191],
| 30.00th=[ 195], 40.00th=[ 199], 50.00th=[ 205], 60.00th=[ 211],
| 70.00th=[ 219], 80.00th=[ 235], 90.00th=[ 290], 95.00th=[ 422],
| 99.00th=[ 908], 99.50th=[ 1400], 99.90th=[ 3920], 99.95th=[ 5792],
| 99.99th=[15936]
bw (KB /s): min=13600, max=18096, per=100.00%, avg=15957.00, stdev=1212.90
lat (usec) : 250=84.46%, 500=12.32%, 750=1.75%, 1000=0.61%
lat (msec) : 2=0.54%, 4=0.22%, 10=0.08%, 20=0.01%, 50=0.01%
cpu : usr=0.32%, sys=5.01%, ctx=65576, majf=0, minf=6
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=65536/w=0/d=0, short=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: io=262144KB, aggrb=15934KB/s, minb=15934KB/s, maxb=15934KB/s, mint=16451msec, maxt=16451msec
Disk stats (read/write):
xvda: ios=65380/0, merge=0/0, ticks=16068/0, in_queue=16064, util=97.36%
実行結果パラメータの意味
- ジョブ単位での結果
| パラメータ名 | 原文 | 解釈 |
|---|---|---|
| io | Number of megabytes io performed | 何バイト分ディスク読み書きしたかを表す |
| bw | Average bandwidth rate | 平均の帯域幅。 |
| iops | Average IOs performed per second | ディスクが1秒当たりに処理できるI/Oアクセスの数である。 IOPSが高ければ高いほど,高性能なディスクと言える。 1回のI/O処理にかかる時間は,平均アクセス時間と データ転送時間を足した数値。 このI/O処理が1秒当たり何回実行できるかがIOPSである 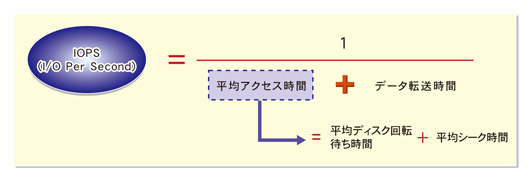 |
| runt | The runtime of that thread | 処理実行時間。 |
| slat | Submission latency (avg being the average, stdev being the standard deviation). This is the time it took to submit the io. For sync io, the slat is really the completion latency, since queue/complete is one operation there. This value can be in milliseconds or microseconds, fio will choose the most appropriate base and print that. In the example above, milliseconds is the best scale. Note: in --minimal mode latencies are always expressed in microseconds. |
Submission latency。リクエスト送信までの遅延時間 |
| clat | Completion latency. Same names as slat, this denotes the time from submission to completion of the io pieces. For sync io, clat will usually be equal (or very close) to 0, as the time from submit to complete is basically just CPU time (io has already been done, see slat explanation). |
completeion latency。リクエスト送信から終了までの遅延時間 |
| bw | Bandwidth. Same names as the xlat stats, but also includes an approximate percentage of total aggregate bandwidth this thread received in this group. This last value is only really useful if the threads in this group are on the same disk, since they are then competing for disk access. |
帯域幅。 |
| cpu | CPU usage. User and system time, along with the number of context switches this thread went through, usage of system and user time, and finally the number of major and minor page faults. |
CPU使用率 |
| IO depths | The distribution of io depths over the job life time. The numbers are divided into powers of 2, so for example the 16= entries includes depths up to that value but higher than the previous entry. In other words, it covers the range from 16 to 31. |
実行時のリクエスト待機状態。submit 以下の行は、IOリクエストまでに要したレイテンシ情報。 |
| IO submit | How many pieces of IO were submitting in a single submit call. Each entry denotes that amount and below, until the previous entry - eg, 8=100% mean that we submitted anywhere in between 5-8 ios per submit call. |
? |
| IO complete | Like the above submit number, but for completions instead. |
? |
| IO issued | The number of read/write requests issued, and how many of them were short. |
? |
| IO latencies | The distribution of IO completion latencies. This is the time from when IO leaves fio and when it gets completed. The numbers follow the same pattern as the IO depths, meaning that 2=1.6% means that 1.6% of the IO completed within 2 msecs, 20=12.8% means that 12.8% of the IO took more than 10 msecs, but less than (or equal to) 20 msecs. |
? |
- グループ単位(Run status group)での結果
| パラメータ名 | 原文 | 解釈 |
|---|---|---|
| io | Number of megabytes io performed. | 何バイト分ディスク読み書きしたかを表す |
| aggrb | Aggregate bandwidth of threads in this group. | 帯域幅のグループ集計 |
| minb | The minimum average bandwidth a thread saw. | 最小帯域幅 |
| maxb | The maximum average bandwidth a thread saw. | 最大帯域幅 |
| mint | The smallest runtime of the threads in that group. | 最小実行時間 |
| maxt | The longest runtime of the threads in that group. | 最大実行時間 |
- ディスク単位(Disk stats (read/write))での結果
| パラメータ名 | 原文 | 解釈 |
|---|---|---|
| ios | Number of ios performed by all groups. | 何バイト分ディスク読み書きしたかを表す |
| merge | Number of merges io the io scheduler. | 解釈 |
| ticks | Number of ticks we kept the disk busy. | リクエストがキューに入っていた数 |
| io_queue | Total time spent in the disk queue. | リクエストがキューに入っていた時間 |
| util | The disk utilization. A value of 100% means we kept the disk busy constantly, 50% would be a disk idling half of the time. |
ディスクアイドル時間(数が多いほどよくディスクを利用できていることになる) |
Amazon Linux AMIのUpdateお知らせ
Amazon Linux AMIにSSHログインすると
Amazon Linux AMIにSSHログインすると、↓のように、パッケージにupdateがあることを知らせてくれる。

とても親切ぅ~。
とりあえず、書かれているURLにアクセスしてどんなupdateがあるか見てみる。
Amazon Linux AMI 2015.09 Release Notes
うーん。英語でいろいろ書かれててよくわからない。 まあ、とりあえず、指示されてる通り、”sudo yum update”してみる。
途中、
Total download size: 95 M Is this ok [y/d/N]:
と聞かれるが、yを選択して進める。
最後に、”Complete!”と出てきて完了!
なんて便利なんだろう。 ありがとうアマゾンさん。
ヒヤリハットであるうちに。その1:プロンプト
たくさんのサーバやインスタンスのコンソールを同時に開くことって、 システム屋さんなら頻繁にあると思います。 そんな時に、今どのサーバを操作しているんだったかな?って混乱することありますよね。
本番サーバに対してテストサーバの設定を間違ってしちゃったりしたら、 そりゃーヒヤリハットじゃすまされないです。
大概は、そんな事故の前に何かしらの方法で今いるサーバを確認します。
unameコマンドでホスト名を確認する。
例えば、
uname -a
コマンドを使って、今操作しているサーバの情報を見たりします。
AWSのAmazonLinuxAMIの場合は以下のような結果になります。
[ec2-user@ip-172-31-26-155 ~]$ uname -a
Linux ip-172-31-26-155 4.1.10-17.31.amzn1.x86_64 #1 SMP Sat Oct 24 01:31:37 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
[ec2-user@ip-172-31-26-155 ~]$
うーん、これを見てもどのインスタンスなのかわからない。。。
[ec2-user@ip-172-31-26-155 ~]$ uname -n
ip-172-31-26-155
ホスト名が視覚的に理解できるものでなく、 割り当てられたローカルIPアドレスになっていた。 これはAWSが自動で割り当ててるのかな。
ではでは。ホスト名をわかりやすいものに変更。
[root@ip-172-31-26-155 ec2-user]# hostname TASUKU-PROD-WEB
もう一度、サーバ情報を見てみると、
[root@ip-172-31-26-155 ec2-user]# uname -a
Linux TASUKU-PROD-WEB 4.1.10-17.31.amzn1.x86_64 #1 SMP Sat Oct 24 01:31:37 UTC 2015 x86_64 x86_64 x86_64 GNU/Linux
ホスト名がわかりやすいもので設定されていていい感じ!
uname -nならホスト名だけなのでもっとわかりやすい。
プロンプトにホスト名を表示させる
いま操作しているコンソールのサーバ情報を毎回コマンドで確認するのはちょっと面倒。 なので、プロンプトに現在操作しているサーバがわかるように設定しよう!と思います。
プロンプトの表示内容が設定されているファイルを開きます。
[ec2-user@ip-172-31-26-155 ~]$ vim ~/.bashrc
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User specific aliases and functions
上記のユーザホームにある.bashrcファイルでは、 グローバル定義の/etc/bashrcを参照するように記述されている。
/etc/bashrcでは、プロンプトに表示する内容を、PS1という変数で 設定しているので、ユーザホームにあるファイルの末尾に、 へPS1を定義してあげればプロンプトの設定を変更できる。
今回は、 『時間 - ユーザ@ホスト名 - ホームからのディレクトリパス』 といった表記になるように以下を設定。
PS1='[\e[0;37m][ [\e[0;32m]\t - [\e[0;33m]\u@\h - [\e[0;36m]\w [\e[0;37m]]'
結果は、

とても見やすくて安心して作業できる。 おまけにクライアントのログ機能で記録しておけば、 時間もわかるのでコマンド履歴だけでなく通常のログとして扱える。
事故を未然に防ぐことには、 効率的で生産的な作業にもつながるのだと実感。
fioコマンドのrwオプション
fioコマンドの公式マニュアルから引用
rw=str Type of io pattern. Accepted values are:
read Sequential reads write Sequential writes randwrite Random writes randread Random reads rw,readwrite Sequential mixed reads and writes randrw Random mixed reads and writes trimwrite Mixed trims and writes. Blocks will be trimmed first, then written to. For the mixed io types, the default is to split them 50/50. For certain types of io the result may still be skewed a bit, since the speed may be different. It is possible to specify a number of IO's to do before getting a new offset, this is done by appending a ':<nr>' to the end of the string given. For a random read, it would look like 'rw=randread:8' for passing in an offset modifier with a value of 8. If the suffix is used with a sequential IO pattern, then the value specified will be added to the generated offset for each IO. For instance, using rw=write:4k will skip 4k for every write. It turns sequential IO into sequential IO with holes. See the 'rw_sequencer' option.
タイプ一覧
| type | 原文 | 解釈 | 設定時注意点 |
|---|---|---|---|
| read | Sequential reads | 連続したブロックの読み取り | |
| write | Sequential writes | 連続したブロックへの書き込み | |
| randwrite | Random writes | ランダムなブロック位置の読み取り | |
| randread | Random reads | ランダムなブロック位置への書き込み | |
| rw,readwrite | Sequential mixed reads and writes | 連続したブロックへの読み込みと書き込み | |
| randrw | Random mixed reads and writes | ランダムなブロック位置への読み込みと書き込み | rwmixreadやrwmixwriteパラメータと組み合わせて、読み書きの割合を調整する。 |
| trimwrite | Mixed trims and writes. Blocks will be trimmed first, then written to. |
?? |
- ※1:シーケンシャルとランダムについては、こちらへ